

Hoofdstuk 6: Schatten en betrouwbaarheidsintervallen: Schatten
 Betrouwbaarheidsinterval voor de Populatieproportie
Betrouwbaarheidsinterval voor de Populatieproportie
Een betrouwbaarheidsinterval voor de populatieproportie #\pi# is een reeks waarden gebaseerd op steekproefgegevens, die zeer aannemelijke kandidaten zijn voor de werkelijke waarde van de populatieproportie.
Om een betrouwbaarheidsinterval te maken voor de populatieproportie #\pi#, zullen we gebruik moeten maken van de steekproefverdeling van de steekproefproportie.
Vergeet niet dat de steekproefproportie #\hat{p}# (ongeveer) de #N\bigg(\pi, \sqrt{\cfrac{\pi \cdot (1-\pi)}{n}}\,\bigg)# verdeling volgt als aan de volgende twee voorwaarden wordt voldaan:
- Er zijn ten minste 10 positieve gevallen: #n\cdot \pi \geq 10#
- Er zijn minstens 10 negatieve gevallen: #n\cdot (1-\pi) \geq 10#
Het probleem is echter dat, aangezien de waarde van #\pi# onbekend is, we deze niet kunnen gebruiken om de voorwaarden voor normaliteit te controleren.
De oplossing is om de steekproefproportie #\hat{p}# te gebruiken als een schatting voor de populatieproportie #\pi# en de voorwaarden voor normaliteit te controleren met #\hat{p}#.
Op dezelfde manier, zonder #\pi# te weten, kunnen we niet de standaardfout van de proportie #\sigma_{\hat{p}}# berekenen. In plaats daarvan zullen we gebruik maken van de geschatte standaardfout van de proportie #s_{\hat{p}}# in de berekening van een betrouwbaarheidsinterval voor de populatieproportie #\pi# :
\[s_{\hat{p}} =\sqrt{\cfrac{\hat{p}\cdot (1-\hat{p})}{n}}\]
De breedte van een betrouwbaarheidsinterval wordt bepaald door de foutmarge.
#\phantom{0}#
Foutmarge
De foutmarge #(ME)# van een betrouwbaarheidsinterval voor de populatieproportie #\pi# is de afstand vanaf het midden van het interval #\hat{p}# tot ofwel de ondergrens #L# of de bovengrens #U#.
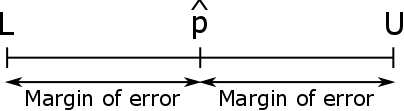
Om de foutmarge van een betrouwbaarheidsinterval te berekenen voor de populatieproportie #\pi# gebruik je de volgende formule:
\[\begin{array}{rcccl}ME &=& z^* \cdot s_{\hat{p}} &=& z^* \cdot \sqrt{\cfrac{\hat{p}\cdot(1-\hat{p})}{n}}\end{array}\]
Waar #z^*# de kritische waarde is van de standaardnormale verdeling zodat #\mathbb{P}(-z^* \leq Z \leq z^*) = \cfrac{C}{100})#.

Het Berekenen van z* met Statistische Software
Laat #C# het betrouwbaarheidsniveau zijn in #\%#.
Om de kritische waarde #z^*# te berekenen in Excel, gebruik je de functie NORM.INV():
\[=\text{NORM.INV}((100+C)/200, 0, 1)\]
Om de kritische waarde #z^*# te berekenen in R, gebruik je de functie qnorm():
\[\text{qnorm}(p=(100+C)/200, mean=0, sd=1,lower.tail = \text{TRUE})\]
Factoren die de Foutmarge Beïnvloeden
De foutmarge van een betrouwbaarheidsinterval voor de populatieproportie #\pi# is afhankelijk van #3# factoren: het betrouwbaarheidsniveau, de steekproefproportie en de steekproefgrootte.
- Als het betrouwbaarheidsniveau toeneemt, neemt de foutmarge toe en wordt het betrouwbaarheidsinterval breder.
- Als de steekproefproportie een waarde van #0.5# (van beide kanten) nadert, neemt de foutmarge toe en wordt het betrouwbaarheidsinterval breder.
- Als de steekproefgrootte toeneemt, neemt de foutmarge af en wordt het betrouwbaarheidsinterval smaller.
Hij selecteert willekeurig een steekproef van #280# uit deze populatie en ontdekt dat #X=28# van hen vegetarisch/veganistisch is.
Bereken de foutmarge van het #93\%# betrouwbaarheidsinterval voor de populatieproportion #\pi#. Rond je antwoord af op #3# decimalen.
#ME=0.032#
Er zijn een aantal verschillende manieren waarop we de foutmarge kunnen berekenen. Klik op een van de panelen om naar een specifieke oplossing te gaan.
De foutmarge van een betrouwbaarheidsinterval voor de populatieproportie #\pi# wordt berekend met de volgende formule:
\[ME=z^* \cdot s_{\hat{p}}\]
Bereken de steekproefproportie #\hat{p}#:
\[\hat{p}=\cfrac{X}{n}=\cfrac{28}{280}=0.10\]
Onderzoek of de steekproefverdeling van de steekproefproportie als ongeveer normaal kan worden beschouwd:
- #n\cdot \hat{p} = 280 \cdot 0.10 = 28 \geq 10#
- #n\cdot (1 -\hat{p}) = 280 \cdot (1-0.10) = 252 \geq 10#
Aangezien aan beide voorwaarden is voldaan, is de steekproefverdeling van de steekproefproportie bij benadering een normale verdeling met parameters #\mu_{\hat{p}}=\pi# en #\sigma_{\hat{p}}=\sqrt{\cfrac{\pi \cdot (1 - \pi)}{n}}#.
Maar omdat de populatieproportie #\pi# onbekend is, kan de standaardfout van de proportie #\sigma_{\hat{p}}# niet worden berekend.
In plaats daarvan gebruiken we de steekproefproportie #\hat{p}# om de geschatte standaardfout van de proportie #s_{\hat{p}}# te berekenen:
\[s_{\hat{p}}=\sqrt{\cfrac{\hat{p} \cdot (1 - \hat{p})}{n}} = \sqrt{\cfrac{0.10 \cdot (1 -0.10)}{280}} = 0.01793\]
Voor een gegeven betrouwbaarheidsniveau #C#, is de kritische waarde #z^*# van de standaard normale verdeling, de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# in Excel te berekenen, gebruik je de volgende functie:
NORM.INV(probability, mean, standard_dev)
- probability: Een kans die overeenkomt met de normale verdeling.
- mean: Het gemiddelde van de verdeling.
- standard_dev: De standaardafwijking van de verdeling.
We hebben hier #C=93#. Dus om #z^*# te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.93#, voer je het volgende commando uit:
\[\begin{array}{c}
=\text{NORM.INV}((100+C)/200, 0, 1)\\
\downarrow\\
=\text{NORM.INV}(193/200, 0, 1)
\end{array}\]
Dit geeft:
\[z^* = 1.81191\]
Met deze informatie kan de foutmarge worden berekend:
\[ME=z^* \cdot s_{\hat{p}} = 1.81191 \cdot 0.01793 = 0.032\]
De foutmarge van een betrouwbaarheidsinterval voor de populatieproportie #\pi# wordt berekend met de volgende formule:
\[ME=z^* \cdot s_{\hat{p}}\]
Bereken de populatieproportie #\hat{p}#:
\[\hat{p}=\cfrac{X}{n}=\cfrac{28}{280}=0.10\]
Onderzoek of de steekproefverdeling van de steekproefproportie als ongeveer normaal kan worden beschouwd:
- #n\cdot \hat{p} = 280 \cdot 0.10 = 28 \geq 10#
- #n\cdot (1 -\hat{p}) = 280 \cdot (1-0.10) = 252 \geq 10#
Aangezien aan beide voorwaarden is voldaan, is de steekproefverdeling van de steekproefproportie bij benadering een normale verdeling met parameters #\mu_{\hat{p}}=\pi# en #\sigma_{\hat{p}}=\sqrt{\cfrac{\pi \cdot (1 - \pi)}{n}}#.
Maar omdat de populatieproportie #\pi# onbekend is, kan de standaardfout van de proportie #\sigma_{\hat{p}}# niet berekend worden.
In plaats daarvan gebruiken we de steekproefproportie om de geschatte standaardfout van de proportie te berekenen: #s_{\hat{p}}#:
\[s_{\hat{p}}=\sqrt{\cfrac{\hat{p} \cdot (1 - \hat{p})}{n}} = \sqrt{\cfrac{0.10 \cdot (1 -0.10)}{280}} = 0.01793\]
Voor een gegeven betrouwbaarheidsniveau #C#, is de kritische waarde #z^*# van de standaard normale verdeling de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# in R te berekenen, gebruik je de volgende functie:
qnorm(p, mean, sd, lower.tail)
- p: Een kans die overeenkomt met de normale verdeling.
- mean: Het gemiddelde van de verdeling.
- sd: De standaardafwijking van de verdeling.
- lower.tail: Indien TRUE (standaard geldt), is de kans #\mathbb{P}(X \leq x)#, anders #\mathbb{P}(X \gt x)#.
We hebben hier #C=93#. Dus om #z^*#te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.93#, voer je het volgende commando uit:
\[\begin{array}{c}
\text{qnorm}(p = (100+C)/200, mean = 0, sd = 1, lower.tail = \text{TRUE})\\
\downarrow\\
\text{qnorm}(p =193/200, mean = 0, sd = 1, lower.tail = \text{TRUE})
\end{array}\]
Dit geeft:
\[z^* = 1.81191\]
Met deze informatie kan de foutmarge worden berekend:
\[ME=z^* \cdot s_{\hat{p}} = 1.81191 \cdot 0.01793 = 0.032\]
#\phantom{0}#
Algemene Formule voor een Betrouwbaarheidsinterval voor de Populatieproportie
Aannemend dat de steekproefverdeling van de steekproefproportie (ongeveer) normaal is, is de algemene formule voor het berekenen van een #C\%\,CI# voor de populatieproportie #\pi#, gebaseerd op een aselecte steekproef van grootte #n#:
\[CI_{\pi}=\bigg(\hat{p} - z^*\cdot \sqrt{\cfrac{\hat{p}\cdot(1-\hat{p})}{n}},\,\,\,\, \hat{p} + z^*\cdot \sqrt{\cfrac{\hat{p}\cdot(1-\hat{p})}{n}} \bigg)\]
Hiervan vertoonden #X=786# kweken enige resistentie tegen penicilline.
Construeer een #90\%# betrouwbaarheidsinterval voor het aandeel streptokokkenkweken onder alle Florida-patiënten die penicillineresistent zijn. Rond je antwoorden af op #3# decimalen.
Er zijn een aantal verschillende manieren waarop we het betrouwbaarheidsinterval kunnen berekenen. Klik op een van de panelen om naar een specifieke oplossing te gaan.
Bereken de steekproefproportie #\hat{p}#:
\[\hat{p}=\cfrac{X}{n}=\cfrac{786}{1786}=0.4401\]
Onderzoek of de steekproefverdeling van de steekproefproportie als ongeveer normaal kan worden beschouwd:
- #n\cdot \hat{p} = 1786 \cdot 0.4401 = 786 \geq 10#
- #n\cdot (1 -\hat{p}) = 1786 \cdot (1-0.4401) = 1000 \geq 10#
Omdat aan beide voorwaarden is voldaan, is de steekproefverdeling van de steekproefproportie bij benadering normaal.
Ervan uitgaande dat de steekproefverdeling van de steekproefproportie (ongeveer) normaal is, is de algemene formule voor het berekenen van een #C\%\,CI# voor de populatieproportie #\pi#, gebaseerd op een willekeurige steekproef van grootte #n# gelijk aan:
\[CI_{\pi}=\bigg(\hat{p} - z^*\cdot \sqrt{\cfrac{\hat{p}\cdot(1-\hat{p})}{n}},\,\,\,\, \hat{p} + z^*\cdot \sqrt{\cfrac{\hat{p}\cdot(1-\hat{p})}{n}} \bigg)\]
Voor een gegeven betrouwbaarheidsniveau #C#, is de kritische waarde #z^*# van de standaard normale verdeling de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# in Excel te berekenen, gebruik je de volgende functie:
NORM.INV(probability, mean, standard_dev)
- probability: Een kans die overeenkomt met de normale verdeling.
- mean: Het gemiddelde van de verdeling
- standard_dev: De standaardafwijking van de verdeling.
We hebben hier #C=90#. Dus om #z^*# te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.90#, voer je het volgende commando uit:
\[\begin{array}{c}
=\text{NORM.INV}((100+C)/200, 0, 1)\\
\downarrow\\
=\text{NORM.INV}(190/200, 0, 1)
\end{array}\]
Dit geeft:
\[z^* = 1.6449\]
Bereken de ondergrens #L# van het betrouwbaarheidsinterval:
\[L = \hat{p} - z^*\cdot \sqrt{\cfrac{\hat{p}\cdot(1-\hat{p})}{n}} = 0.4401 - 1.6449 \cdot \sqrt{\cfrac{0.4401 \cdot (1-0.4401)}{1786}} = 0.421\]
Bereken de bovengrens #U# van het betrouwbaarheidsinterval:
\[U = \hat{p} + z^*\cdot \sqrt{\cfrac{\hat{p}\cdot(1-\hat{p})}{n}} = 0.4401 + 1.6449 \cdot \sqrt{\cfrac{0.4401 \cdot (1-0.4401)}{1786}} = 0.459\]
Dus het #90\%# betrouwbaarheidsinterval voor de populatieproportie #\pi# is:
\[CI_{\pi,\,90\%}=(0.421,\,\,\, 0.459)\]
Bereken de steekproefproportie #\hat{p}#:
\[\hat{p}=\cfrac{X}{n}=\cfrac{786}{1786}=0.4401\]
Onderzoek of de steekproefverdeling van de steekproefproportie als ongeveer normaal kan worden beschouwd:
- #n\cdot \hat{p} = 1786 \cdot 0.4401 = 786 \geq 10#
- #n\cdot (1 -\hat{p}) = 1786 \cdot (1-0.4401) = 1000 \geq 10#
Omdat aan beide voorwaarden is voldaan, is de steekproefverdeling van de steekproefproportie bij benadering normaal.
Ervan uitgaande dat de steekproefverdeling van de steekproefproportie (ongeveer) normaal is, is de algemene formule voor het berekenen van een #C\%\,CI# voor de populatieproportie #\pi#, gebaseerd op een willekeurige steekproef van grootte #n#, gelijk aan:
\[CI_{\pi}=\bigg(\hat{p} - z^*\cdot \sqrt{\cfrac{\hat{p}\cdot(1-\hat{p})}{n}},\,\,\,\, \hat{p} + z^*\cdot \sqrt{\cfrac{\hat{p}\cdot(1-\hat{p})}{n}} \bigg)\]
Voor een gegeven betrouwbaarheidsniveau #C#, is de kritische waarde #z^*# van de standaard normale verdeling, de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# in R te berekenen, gebruik je de volgende functie:
qnorm(p, mean, sd, lower.tail)
- p: Een kans die overeenkomt met de normaalverdeling.
- mean: Het gemiddelde van de verdeling
- sd: De standaardafwijking van de verdeling.
- lower.tail: Indien TRUE (standaard), is de kans #\mathbb{P}(X \leq x)#, anders #\mathbb{P}(X \gt x)#.
We hebben hier #C=90#. Dus om #z^*#te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.90#, voer je het volgende commando uit:
\[\begin{array}{c}
\text{qnorm}(p = (100+C)/200, mean = 0, sd = 1, lower.tail = \text{TRUE})\\
\downarrow\\
\text{qnorm}(p =190/200, mean = 0, sd = 1, lower.tail = \text{TRUE})
\end{array}\]
Dit geeft:
\[z^* = 1.6449\]
Bereken de ondergrens #L# van het betrouwbaarheidsinterval:
\[L = \hat{p} - z^*\cdot \sqrt{\cfrac{\hat{p}\cdot(1-\hat{p})}{n}} = 0.4401 - 1.6449 \cdot \sqrt{\cfrac{0.4401 \cdot (1-0.4401)}{1786}} = 0.421\]
Bereken de bovengrens #U# van het betrouwbaarheidsinterval:
\[U = \hat{p} + z^*\cdot \sqrt{\cfrac{\hat{p}\cdot(1-\hat{p})}{n}} = 0.4401 + 1.6449 \cdot \sqrt{\cfrac{0.4401 \cdot (1-0.4401)}{1786}} = 0.459\]
Dus het #90\%# betrouwbaarheidsinterval voor de populatieproportie #\pi# is:
\[CI_{\pi,\,90\%}=(0.421,\,\,\, 0.459)\]
#\phantom{0}#
Het Beheersen van de Foutmarge
Stel dat je wil dat de foutmarge voor een #C\%# betrouwbaarheidsinterval voor de populatieproportie #\pi# niet groter is dan #k#.
Dan moet de minimale steekproefomvang
\[n=0.25 \cdot \Big(\cfrac{z^*}{k}\Big)^2,\]
zijn, omhoog afgerond naar het volgende gehele getal.
Als de onderzoeker wil dat de foutmarge van het #94\%# betrouwbaarheidsinterval voor de populatieproportie #\pi# niet groter is dan #0.03#, wat is dan de minimale steekproefgrootte die ze nodig heeft om dit doel te bereiken?
#n \geq 983#
Er zijn een aantal verschillende manieren waarop we de minimale steekproefgrootte kunnen berekenen. Klik op een van de panelen om een specifieke oplossing te kiezen.
Voor een gegeven betrouwbaarheidsniveau #C#, is de kritische waarde #z^*# van de standaard normale verdeling de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# in Excel te berekenen, maak je gebruik van de volgende functie:
NORM.INV(probability, mean, standard_dev)
- probability: Een kans die overeenkomt met de normale verdeling.
- mean: Het gemiddelde van de verdeling
- standard_dev: De standaardafwijking van de verdeling.
We hebben hier #C=94#. Dus om #z^*# te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.94#, voer je het volgende commando uit:
\[\begin{array}{c}
=\text{NORM.INV}((100+C)/200, 0, 1)\\
\downarrow\\
=\text{NORM.INV}(194/200, 0, 1)
\end{array}\]
Dit geeft:
\[z^* = 1.8808\]
Met deze informatie kan de minimale steekproefgrootte als volgt worden berekend:
\[n=0.25 \cdot \Big(\cfrac{z^*}{k}\Big)^2=\Big(\cfrac{1.8808}{0.03}\Big)^2=982.607\]
Als je deze waarde naar boven afrondt, krijg je #n=983#.
Dus om de foutmarge niet groter te laten zijn dan #0.03#, heb je een steekproefgrootte nodig van ten minste #983#.
Voor een gegeven betrouwbaarheidsniveau #C#, is de kritische waarde #z^*# van de standaard normale verdeling de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# in R te berekenen, gebruik je de volgende functie:
qnorm(p, mean, sd, lower.tail)
- p: Een kans die overeenkomt met de normale verdeling.
- mean: Het gemiddelde van de verdeling.
- sd: De standaardafwijking van de verdeling.
- lower.tail: Indien TRUE (standaard), is de kans #\mathbb{P}(X \leq x)#, anders #\mathbb{P}(X \gt x)#.
We hebben hier #C=94#. Dus om #z^*#te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.94#, voer je het volgende commando uit:
\[\begin{array}{c}
\text{qnorm}(p = (100+C)/200, mean = 0, sd = 1, lower.tail = \text{TRUE})\\
\downarrow\\
\text{qnorm}(p =194/200, mean = 0, sd = 1, lower.tail = \text{TRUE})
\end{array}\]
Dit geeft:
\[z^* = 1.8808\]
Met deze informatie kan de minimale steekproefgrootte als volgt worden berekend:
\[n=0.25 \cdot \Big(\cfrac{z^*}{k}\Big)^2=\Big(\cfrac{1.8808}{0.03}\Big)^2=982.607\]
Als je deze waarde naar boven afrondt, krijg je #n=983#.
Dus om de foutmarge niet groter te laten zijn dan #0.03#, heb je een steekproefgrootte nodig van ten minste #983#.

omptest.org als je een OMPT examen moet maken.

